
时间:2024-06-12
SQL优化,算是数据库优化的一个子集。
因此,吹大牛的候选人简历上,会赫然写着”擅长MySQL数据库优化“,而吹小牛的候选人简历上,往往会写”擅长SQL优化“。
但结局是殊途同归的,就是当问他们用什么方式做的优化,他们都会说上三个字:”加索引“。
当然,好一点儿的会说可以加联合索引,它有最左前缀匹配原则(8.0以后的版本就不完全对了)之类的,还能说说覆盖索引。
那么,我的这篇文章,就好好聊聊这个面试话题。
强烈建议近期有求职诉求的Javaer好好看看。
先教大家一个小窍门,最好大家在回答面试官这个问题的时候,最好可以做到跟自己简历中项目的进行真实场景带入,这样会给面试官一种可以理论结合实践的感觉,是个大大的加分项。
举个例子,话术为:
“当时我负责电商平台的商品中心优化,我发现在展示商品列表的时候,一旦深分页就会出现加载缓慢的问题,然后我就看了一下对应的SQL语句,是这样写的:
select id, name, status, detail from product limit 10, 30;
那么一旦在深分页的话,SQL语句就会变成这样:
select id, name, status, detail from product limit 100000, 30;
那么MySQL的执行方式为:一共需要查100030条数据,然后丢弃前面的100000条,只返回后面的30条数据,这样做是非常浪费资源的。
于是我把SQL改为:
select id, name, status, detail from product where id > 100000 limit 30;
100000为上次分页中最大的商品ID,先找到它,然后再根据主键ID扫描后续30条数据。
这样做性能很高,把SQL语句从原先的耗时4300ms,降低到了18ms。”
好了,下面我正式给大家列举一下,SQL优化的N种技巧,select * 这种的就不写了哈。
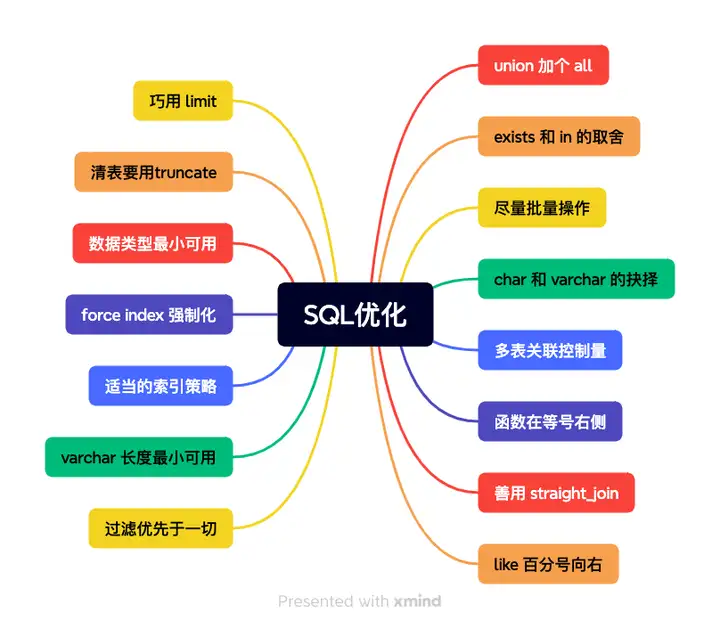
1、巧用limit
上文已经讲解了,仔细看下即可。
2、like百分号向右
反例:
select * from employee where address like '%通州区%';
select * from employee where address like '%通州区';
正解:
select * from employee where address like '%北京市通州区';
原因:
(1)全模糊查询,或者左边出现%的模糊查询,会导致索引实效,应该尽量从查询方式或表结构设计上避免。
(2)若无法避免,且数据量庞大的情况下,一定要使用ElasticSearch进行替代。
3、union 加个 all
反例:
select product_id from orders where id = 100
union
select product_id from orders where id = 200;
正解:
select product_id from orders where id = 100
union all
select product_id from orders where id = 200;
原因:
union:对两个结果集进行并集操作,不包括重复行,相当于distinct,同时进行默认规则的排序;
union all:对两个结果集进行并集操作,包括重复行,不进行排序;
union因为要进行重复值扫描,所以在结果集庞大的情况下,效率极低,因此建议使用union all。
若结果集去重是强需求,则在应用程序代码上进行去重,因为数据库资源要比应用服务器资源更加珍贵。
4、善用 staright_join
straight_join功能同inner join类似,但能让左边的表来驱动右边的表,通过改变优化器对于联表查询的执行顺序的方式,获取更好的性能。
btw:若驱动表(左边)的数据量小于(被驱动表),它的执行性能要高于,驱动表(左边)的数据量大于(被驱动表)。
举个例子:
select * from t2 straight_join t1 on t2.a = t1.a;
比如上面这个,如果我们事先知道t2表的数据量一定小于t1表的话,就可以使用上面的方式指定t2表为驱动表。
需要注意的点:
(1)straight_join只适用于inner join,并不适用于left join,right join。
(2)大部分情况下,MySQL优化器是可以做出正解的。因此,使用straight_join一定要慎重,因为部分情况下人为指定的执行顺序并不一定会比优化引擎要靠谱。
5、exists 和 in 的取舍
select * from student where school_id in (select id from school);
select * from police p where exists (select 1 from user u where u.id = p.id);
如果子查询得出的结果集数据较少,主查询中的表较大且又有索引时,应该用in;反之,如果外层的主查询数据较少,子查询中的表大,又有索引时使用exists。
如果是exists,那么以外层表为驱动表,先被访问。
如果是in,那么先执行子查询。
in 是把外表和内表作 hash 连接,而 exists 是对外表作 loop 循环,每次 loop 循环再对内表进行查询。所以,我们会以驱动表的快速返回为目标,目标是以小表驱动大表,这是性能优化的本质。
之前有一种比较扯淡的说法,“exists 比 in 效率高”,大家试想一下,如何一个事物在任何场景下,都优于另外一个事物,那另外一个事物就没有存在的必要性了。
6、清表要用truncate
反例:
delete from user;
正解:
truncate user;
原因:
(1)truncate是直接把表删除,然后再重建表结构,性能很高,但删除操作记录不记入日志,不能回滚。
delete语句执行删除的过程是每次从表中删除一行,性能较低,但该行的删除操作会作为事务记录在日志中保存,以便进行进行回滚操作。
(2)truncate后,表和索引所占用的空间会恢复到初始大小,而delete只是将被删除的记录标记为已删除,不会立即减少表或索引所占用的空间。
7、尽量批量操作
反例:
insert into student(name, sex, age) values('Tom', 1, 20);
insert into student(name, sex, age) values('Tony', 1, 18);
正解:
insert into student(name, sex, age) values('Tom', 1, 20), ('Tony', 1, 18);
原因:
SQL批量操作,即一次数据库操作中插入多个数据行,相比于单条插入,可减少大量的IO交互和SQL解析开销,从而提高了插入效率。
8、过滤优先于一切
反例
select city, avg(area) from country group by city having city ='beijing' or city = 'shanghai';
正解:
select city, avg(area) from country where city ='beijing' or city = 'shanghai' group by city;
原因: 记住,无论是分组还是排序,或者多表join,如果可以的话,第一件事就是把用不到的记录先过滤掉。
9、函数在等号右侧
反例:
select * from article where left(title, 4) = '环球资讯';
正解:
select * from article where title = left('环球资讯', 4);
原因: 如果在索引列上使用函数,会导致索引实效。
10、数据类型最小可用
一般情况下,应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常会使SQL执行更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少。
但是,要确保没有低估需要存储的值的范围,因为在表schema中修改数据类型是一件非常耗时和痛苦的操作(特指表数据量很大的场景)。如果无法确定哪个数据类型是最好的,就选择你认为不会超过范围的最小类型。
举个例子:如果确定只需要存0—200,tinyint unsigned类型是最适合的。
11、char 和 varchar的抉择
char:定长,存取效率高,一般用于固定长度的表单提交数据存储,例如:身份证号,手机号,电话,密码等,长度不够的时候,会采取右补空格的方式。
varchar:不定长,更节省空间,需要用一个或者两个字节来存储数据的长度。具体规则是:如果列的最大长度小于或等于255字节,则只使用1个字节表示,否则使用2个字节。
varchar由于行是变长的,在UPDATE时可能使行变得比原来更长,会导致分裂页和产生碎片。
12、varchar长度最小可用
有人认为,既然varchar是变长的,那我就尽量给它设置得大一些,以备不时之需,反正没有坏处。
其实,varchar(5) 和 varchar(200)是不一样的!
我们看下《高性能MySQL》一书中的原话:

因此,当你把varchar的长度调整为最小可用,是可以帮助你优化SQL排序性能的。
13、适当的索引策略
频繁作为查询条件的字段应该创建索引,频繁更新的字段不适合创建索引;
多表关联查询中的关联字段,查询中统计或者分组字段,查询中排序字段,应该创建索引;
尽量使用数据量少或区分度高的字段创建索引;
多条件组合查询优先创建组合索引,熟悉组合索引的最左前缀原则,不要创建冗余索引;
禁止使用全文索引,可以用前缀索引进行替代;
善于利用覆盖索引来优化查询;
delete和update语句的where条件必须由索引,否则会导致锁表;
适当的索引策略,经过业务取舍后,可以使SQL执行得更快。
14、force index强制化
MySQL查询优化器在执行SQL语句时,会选择它认为最合适的索引,但有时却并不准确,不是实际上最快的索引,此时可以用force index人为指定索引。
force index 跟着表名后面,用于强制使用指定的索引名(key)。
如下列所示:
select * from msg force index(idx_dest_src) where dest = '18736809673' and src in ('15144804019', '18674654894');
15、多表关联控制量
据说,阿里巴巴开发者手册规定,join表的数量不应该超过3个,这个我还真没看到。
我个人觉得,多表关联需要控制量,但没必要完全一杆子拍死。
如果某个系统中,有很多多表关联的大SQL,那确实意味着表结构设计有问题,或者需要引入ES等技术方案了。
结语
整体就这么多,后续如果有新的,我再补充。
Copyright © 2019-2025 21329.com


 在线咨询
在线咨询 18842938855
18842938855